CAIDA’s 2016 Annual Report
Tuesday, May 9th, 2017 by kc[Executive summary and link below]
The CAIDA annual report summarizes CAIDA’s activities for 2016, in the areas of research, infrastructure, data collection and analysis. Our research projects span Internet topology, routing, security, economics, future Internet architectures, and policy. Our infrastructure, software development, and data sharing activities support measurement-based internet research, both at CAIDA and around the world, with focus on the health and integrity of the global Internet ecosystem. The executive summary is excerpted below:
Mapping the Internet. We continued to expand our topology mapping capabilities using our Ark measurement infrastructure. We improved the accuracy and sophistication of our topology annotations, including classification of ISPs, business relationships between them, and geographic mapping of interdomain links that implement these relationships. We released two Internet Topology Data Kits (ITDKs) incorporating these advances.
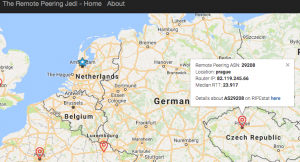
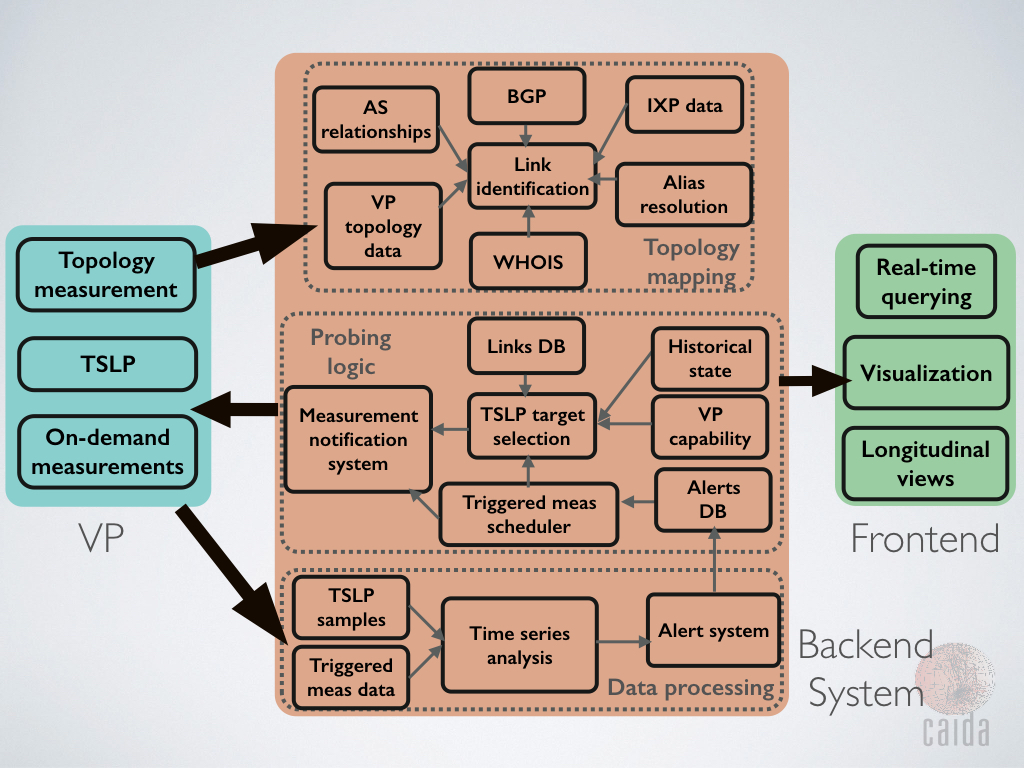
Mapping Interconnection Connectivity and Congestion. We continued our collaboration with MIT to map the rich mesh of interconnection in the Internet in order to study congestion induced by evolving peering and traffic management practices of CDNs and access ISPs. We focused our efforts on the challenge of detecting and localizing congestion to specific points in between networks. We developed new tools to scale measurements to a much wider set of available nodes. We also implemented a new database and graphing platform to allow us to interactively explore our topology and performance measurements. We produced related data collection and analyses to enable evaluation of these measurements in the larger context of the evolving ecosystem: infrastructure resiliency, economic tussles, and public policy.
Monitoring Global Internet Security and Stability. We conducted infrastructure research and development projects that focus on security and stability aspects of the global Internet. We developed continuous fine-grained monitoring capabilities establishing a baseline connectivity awareness against which to interpret observed changes due to network outages or route hijacks. We released (in beta form) a new operational prototype service that monitors the Internet, in near-real-time, and helps identify macroscopic Internet outages affecting the edge of the network.
CAIDA also developed new client tools for measuring IPv4 and IPv6 spoofing capabilities, along with services that provide reporting and allow users to opt-in or out of sharing the data publicly.
Future Internet Architectures. We continued studies of IPv4 and IPv6 paths in the Internet, including topological congruency, stability, and RTT performance. We examined the state of security policies in IPv6 networks, and collaborated to measure CGN deployment in U.S. broadband networks. We also continued our collaboration with researchers at several other universities to advance development of a new Internet architecture: Named Data Networking (NDN) and published a paper on the policy and social implications of an NDN-based Internet.
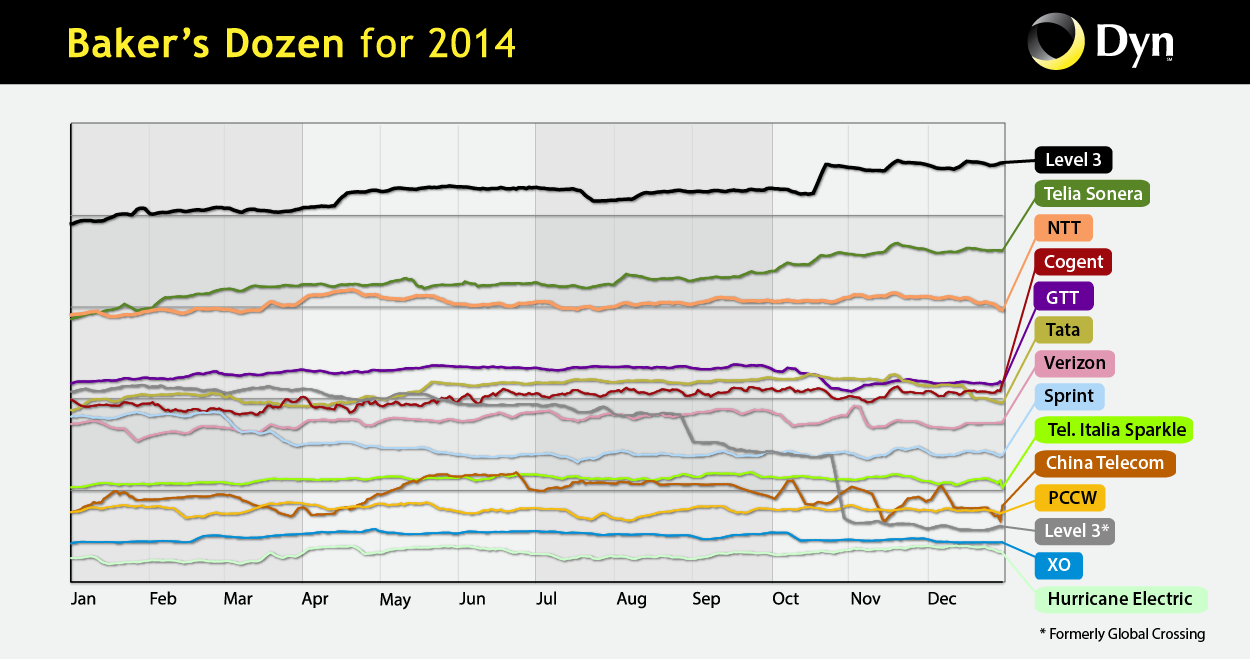
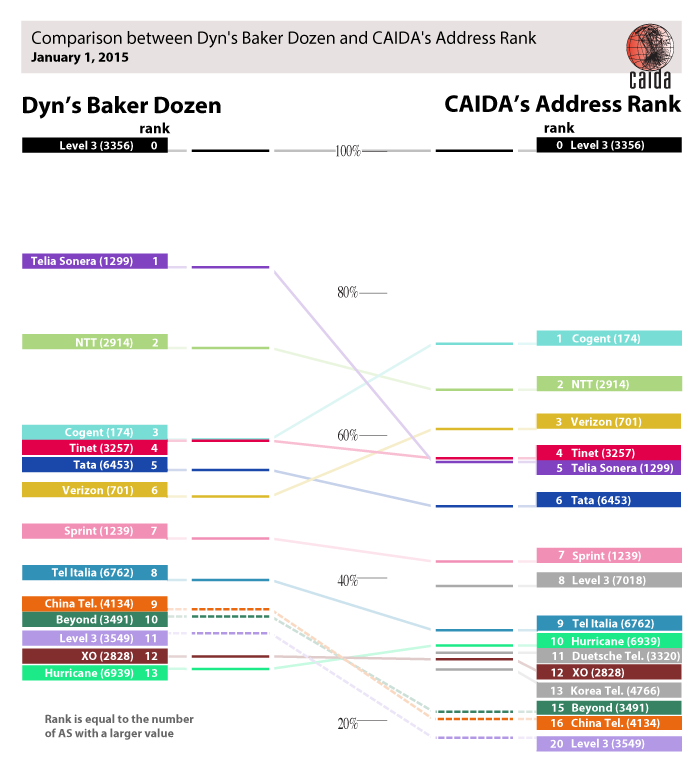
Public Policy. Acting as an Independent Measurement Expert, we posted our agreed-upon revised methodology for measurement methods and reporting requirements related to AT&T Inc. and DirecTV merger (MB Docket No. 14-90). We published our proposed method and a companion justification document. Inspired by this experience and a range of contradicting claims about interconnection performance, we introduced a new model describing measurements of interconnection links of access providers, and demonstrated how it can guide sound interpretation of interconnection-related measurements regardless of their source.
Infrastructure operations. It was an unprecedented year for CAIDA from an infrastructure development perspective. We continued support for our existing active and passive measurement infrastructure to provide visibility into global Internet behavior, and associated software tools and platforms that facilitate network research and operational assessments.
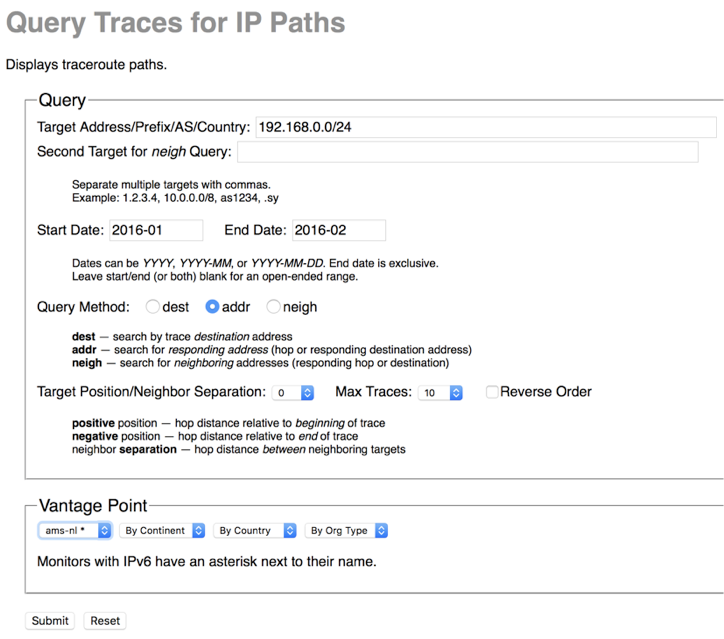
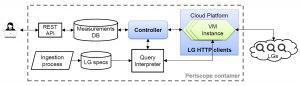
We made available several data services that have been years in the making: our prototype Internet Outage Detection and Analysis service, with several underlying components released as open source; the Periscope platform to unify and scale querying of thousands of looking glass nodes on the global Internet; our large-scale Internet topology query system (Henya); and our Spoofer system for measurement and analysis of source address validation across the global Internet. Unfortunately, due to continual network upgrades, we lost access to our 10GB backbone traffic monitoring infrastructure. Now we are considering approaches to acquire new monitors capable of packet capture on 100GB links.
As always, we engaged in a variety of tool development, and outreach activities, including maintaining web sites, publishing 13 peer-reviewed papers, 3 technical reports, 4 workshop reports, one (our first) BGP hackathon report, 31 presentations, 20 blog entries, and hosting 6 workshops (including the hackathon). This report summarizes the status of our activities; details about our research are available in papers, presentations, and interactive resources on our web sites. We also provide listings and links to software tools and data sets shared, and statistics reflecting their usage. Finally, we report on web site usage, personnel, and financial information, to provide the public a better idea of what CAIDA is and does.
For the full 2016 annual report, see http://www.caida.org/home/about/annualreports/2016/
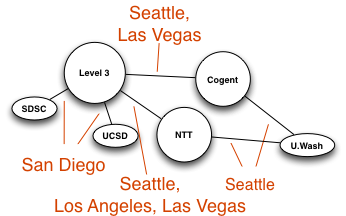
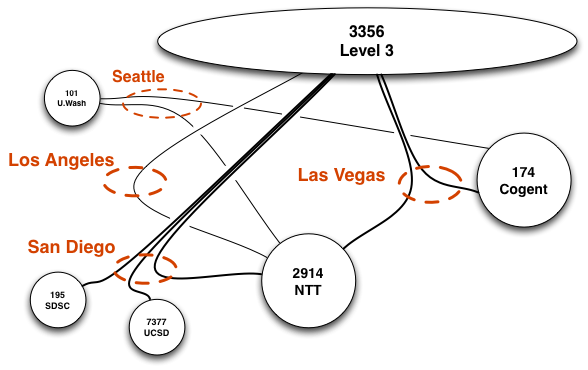


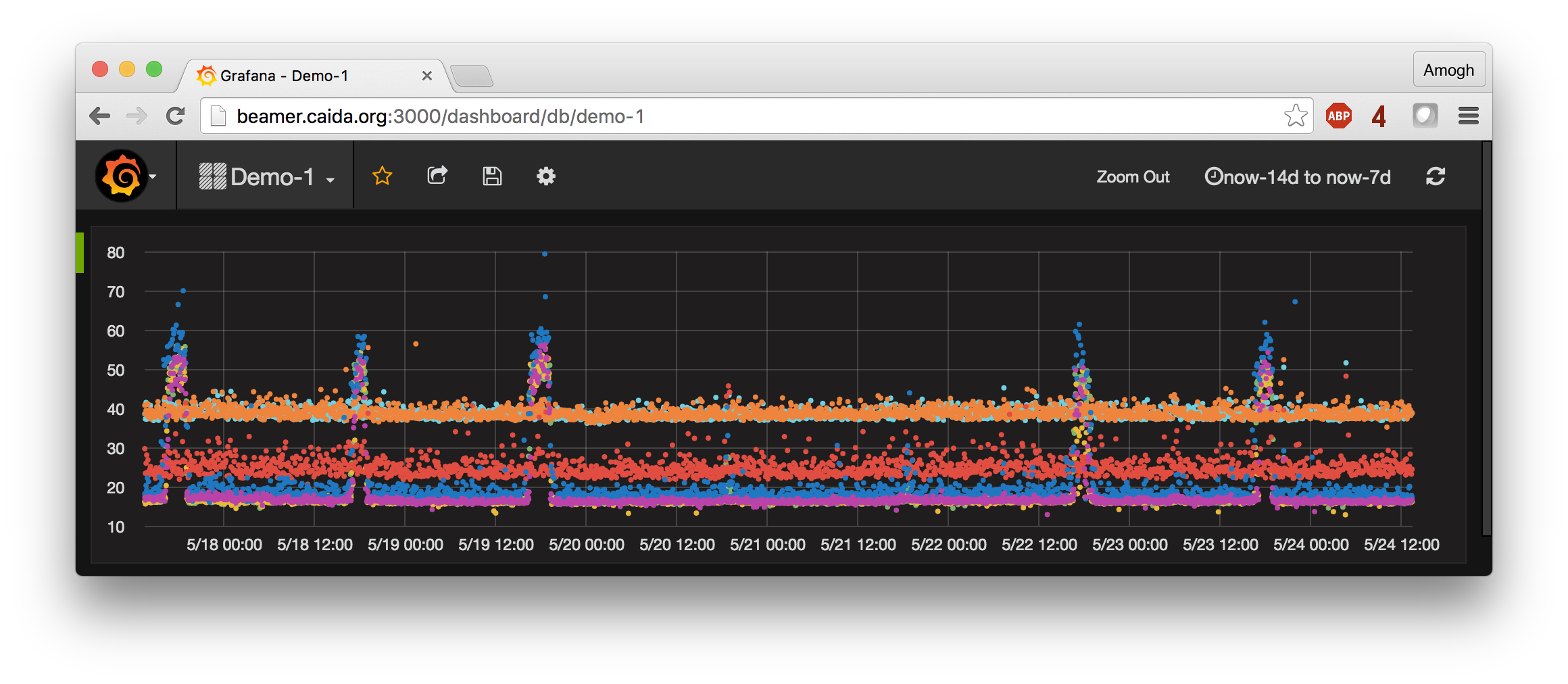
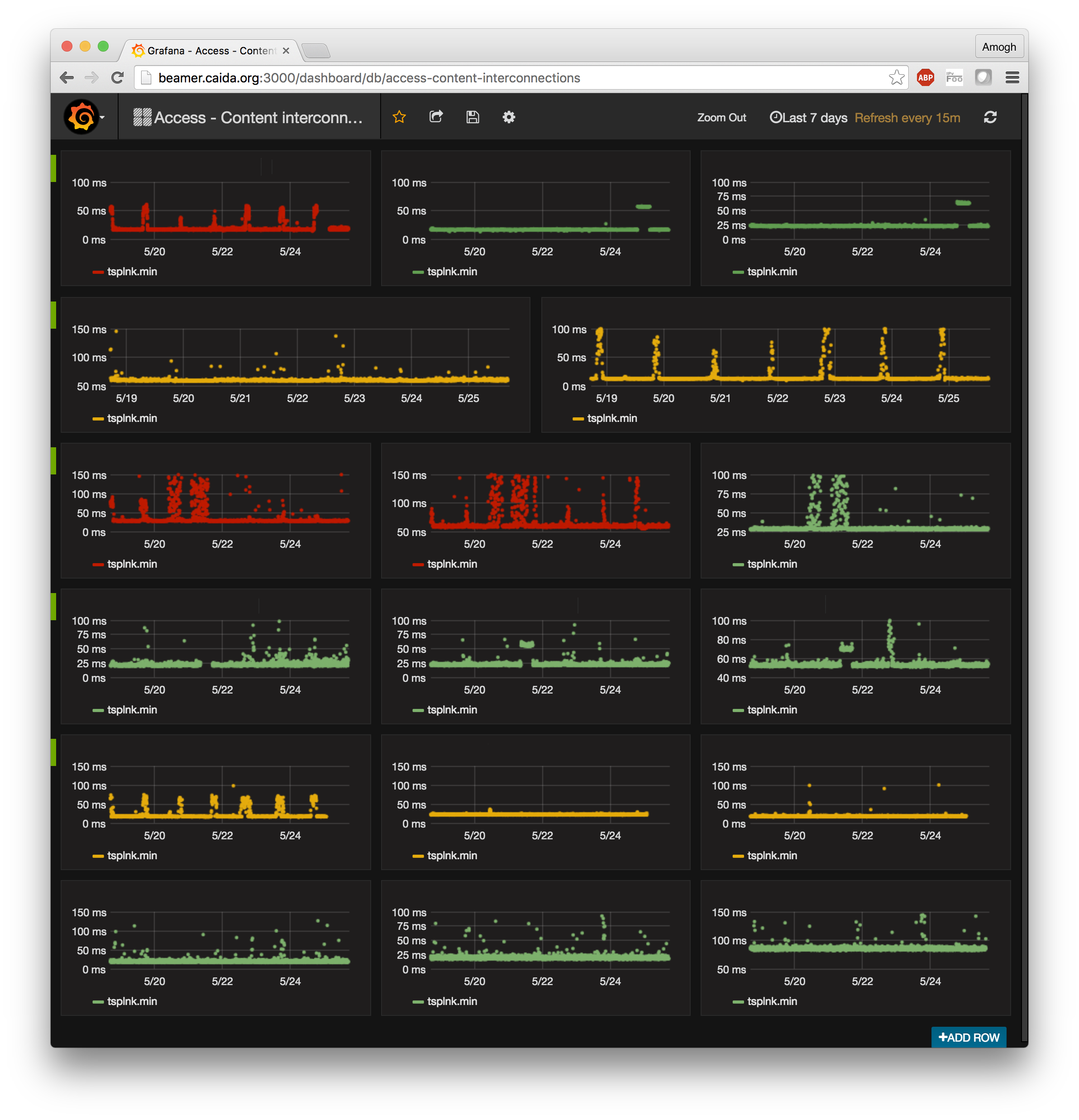
 Hilbert map visulization shows utilization of IPv4 address space, rendered in two dimensions using as space-filling continous fractal Hilbert curve of order 12. Each pixel in the full resolution image represents a /24 block; red indicates used blocks, green unassigned blocks and blue RFC special blocks. Routed unused blocks are grey and unrouted assigned black
Hilbert map visulization shows utilization of IPv4 address space, rendered in two dimensions using as space-filling continous fractal Hilbert curve of order 12. Each pixel in the full resolution image represents a /24 block; red indicates used blocks, green unassigned blocks and blue RFC special blocks. Routed unused blocks are grey and unrouted assigned black