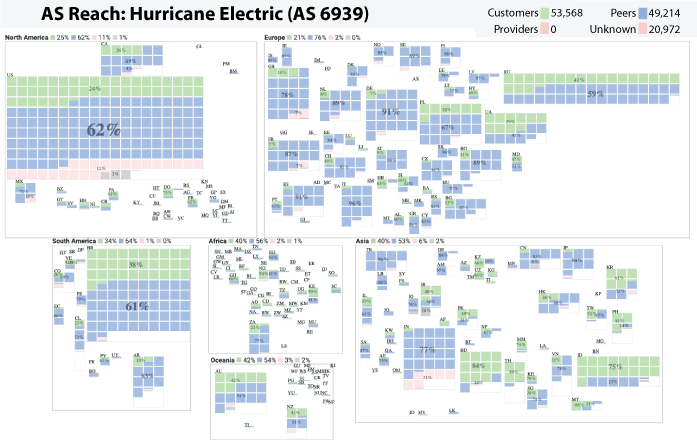
AS Reachability Visualization
Wednesday, December 4th, 2024 by Bradley HuffakerThe AS Reach Visualization provides a geographic breakdown of the number of ASes reachable through an AS’s customer, peers, providers, or an unknown neighbor. The interactive interface to the visualization can be found at https://www.caida.org/catalog/media/visualizations/as-reach/
Independent networks (Autonomous Systems, or ASes) engage in typically voluntary bilateral interconnection (“peering”) agreements to provide reachability to each other for some subset of the Internet. The implementation of these agreements introduces a non-trivial set of constraints regarding paths over which Internet traffic can flow, with implications for network operations, research, and evolution. Realistic models of Internet topology, routing, workload, and performance
must account for the underlying economic dynamics.
Although these business agreements between ISPs can be complicated, the original model introduced by Gao (On inferring autonomous system relationships in the Internet), abstracts business relationships into the following three most common types:
- customer-to provider: in which a customer network gets access to the internet from a provider network
- provider-to-customer: the reverse of the customer-to-provider, the provider provides access to it’s customer
- peer-to-peer: where both ASes exchange traffic between their customers
An AS’s Reach is defined as the set of ASes the target AS can reach through its customers, peers, providers, or unknown. The Customer Reach is the set of ASes reachable through the AS’s customers. The Peer Reach is the set of ASes that are not in the Customer Reach, but reachable through the AS’s peers. The Provider Reach is the set of ASes not in the Customer or Peer Reach, but reachable through the AS’s provider. The Unknown Reach is the set of ASes not in the Customer, Peer, or Provider Reach. More details at https://www.caida.org/catalog/media/visualizations/as-reach/