This is the first in a series of essays about CAIDA’s new effort to reduce the barrier to performing a variety of Internet measurements.
Network operators and researchers often require the ability to conduct active measurements of networks from a specific location in order to understand some property of the network. However, obtaining access to a vantage point at a given location is challenging, as there can be significant trust barriers that prevent access: a platform operator has to provide vantage point hosts with guarantees about the activity that their vantage points will exhibit, and a platform operator has to trust that users will stay within those guarantees. Current access control to active measurement infrastructure has two extremes: access that allows for trusted users to run arbitrary code, and API access that allows arbitrary users to schedule a (limited) set of measurements, and obtain their results. Prior research thrusts in active measurement design have focused on interfaces that allow a user to request a host to send arbitrary packets, leaving the implementation of the measurement to the user. However, this design pattern limits the guarantees that a platform operator can provide a vantage point host regarding what their vantage point will actually do. A domain-specific language for conducting active measurements can alleviate these concerns because it (1) allows a platform operator to specify the measurements that a user can run, and communicate to the host what their vantage point will do, (2) provides users reference implementations of measurement applications that act as building blocks to more complex measurements.
Over the past six months, in consultation with members of the active measurement community, CAIDA has been working towards a next-generation measurement infrastructure, built on the existing Archipelago (Ark) platform. One aspect of this platform is the notion of a researcher development environment that allows for complex, distributed, and reactive measurements built on a well-defined set of measurement primitives. In an effort to make the Ark platform easier to use for measurement researchers, while also providing important access control, CAIDA has developed the scamper python module that provides an interface to the measurement primitives available on each of the Ark nodes. Today, we are releasing the source code of that module, so that researchers can develop and test complex measurements locally, before running vetted experiments on Ark.
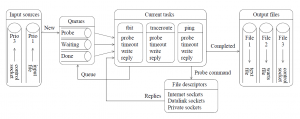
The architecture of scamper. Measurement tasks are supplied from one or more input sources, including from an input file, from the command line, or from a control socket.
The module provides user-friendly interfaces to existing scamper functionality. We illustrate the module with some examples.
Example #1: Implementation of RTT-based geolocation measurement
The following is an implementation of the well-known single-radius measurement, which conducts delay measurements to an IP address from a distributed set of vantage points, and reports the shortest of all the RTTs obtained with the name of the monitor, which on Ark, is derived from its location (e.g., lax-us, hlz2-nz, ams-nl, and so on). Researchers and operators might use this technique to understand approximately where a system is located, using the RTT constraint of the vantage point that reports the shortest delay.
01 import sys
02 from datetime import timedelta
03 from scamper import ScamperCtrl
04
05 if len(sys.argv) != 3:
06 print("usage: single-radius.py $dir $ip")
07 sys.exit(-1)
08
09 ctrl = ScamperCtrl(remote_dir=sys.argv[1])
10 for i in ctrl.instances():
11 ctrl.do_ping(sys.argv[2], inst=i)
12
13 min_rtt = None
14 min_vp = None
15 for o in ctrl.responses(timeout=timedelta(seconds=10)):
16 if o.min_rtt is not None and (min_rtt is None or min_rtt > o.min_rtt):
17 min_rtt = o.min_rtt
18 min_vp = o.inst
19
20 if min_rtt is not None:
21 print(f"{min_vp.name} {(min_rtt.total_seconds()*1000):.1f} ms")
22 else:
23 print(f"no responses for {sys.argv[2]}")
This implementation takes two parameters (lines 5-7) — a directory that contains a set of unix domain sockets, each of which represents an interface to a single vantage point, and an IP address to probe. On line 9, we open an interface (represented by a ScamperCtrl object) that contains all of the vantage points in that directory. We then send a ping measurement to each of the vantage point instances (lines 10-11). These ping measurements operate in parallel — the ping measurements on each of the nodes operate asynchronously. We then collect the results of the measurements (lines 13-18), noting the minimum observed RTT, and the vantage point where it came from. We pass a 10-second timeout on line 15, so that a vantage point that experiences an outage after we send the measurements does not hold up the whole experiment. Finally, on lines 20-23, we print the result of the measurement.
Example #2: RTTs to authoritative name servers of a specific domain
The next example shows a more complex measurement. Let’s say we want to know the RTTs to the authoritative name servers for a zone from a single vantage point.
01 import sys
02 from datetime import timedelta
03 from scamper import ScamperCtrl
04
05 if len(sys.argv) != 3:
06 print("usage: authns-delay.py $vp $zone")
07 sys.exit(-1)
08
09 ctrl = ScamperCtrl(remote=sys.argv[1])
10
11 # get the list of NS for the zone
12 o = ctrl.do_dns(sys.argv[2], qtype='NS', wait_timeout=1, sync=True)
13
14 # issue queries for the IP addresses of the authoritative servers
15 ns = {}
16 for rr in o.ans():
17 if rr.ns is not None and rr.ns not in ns:
18 ns[rr.ns] = 1
19 ctrl.do_dns(rr.ns, qtype='A', wait_timeout=1)
20 ctrl.do_dns(rr.ns, qtype='AAAA', wait_timeout=1)
21
22 # collect the unique addresses out of the address lookups
23 addr = {}
24 for o in ctrl.responses(timeout=timedelta(seconds=3)):
25 for a in o.ans_addrs():
26 addr[a] = o.qname
27
28 # collect RTTs for the unique IP addresses
29 for a in addr:
30 ctrl.do_ping(a)
31 for o in ctrl.responses(timeout=timedelta(seconds=10)):
32 print(f"{addr[o.dst]} {o.dst} " +
33 (f"{(o.min_rtt.total_seconds() * 1000):.1f}"
34 if o.min_rtt is not None else "???"))
This implementation takes two parameters (lines 5-7) — a single vantage point, and a zone name to study. As before, we open an interface to that VP on line 9, and then issue a DNS query for the authoritative name servers for the zone (line 12).
There are a couple of interesting things to note about line 12. First, we do not pass a handle representing the VP instance to the do_dns method, as the ScamperCtrl interface only has a single instance associated with it — it is smart enough to use that single instance for the measurement. Second, we pass sync=True to make the measurement synchronous — the method does not return until it has the results of that single measurement. This is shorter (in lines of code) and more readable than issuing an asynchronous measurement and then collecting the single result. Then, we issue asynchronous queries for the IPv4 and IPv6 addresses for the name servers returned (lines 14-20) and send ping measurements for each of the addresses (lines 29-30). Finally, we print the names of the nameservers, their IP addresses, and the minimum RTT observed to each.
The scamper python module supports most of the measurement primitives currently available in scamper: ping, traceroute, DNS query, alias resolution, HTTP, and simple UDP probes. We’ve used the module internally to: (1) reproduce the data collection methodology of a recent router fingerprinting method; (2) study the deployment of Netflix fast.com speed test endpoints, (3) implement MIDAR; (4) study anycast open resolvers, and (5) monitor serial number changes of zones amongst a set of nameservers authoritative for a zone. One important feature of our module is that it provides a python interface, which means that you can use our measurement module alongside existing python modules that parse JSON, etc. The documentation for the module is publicly available and we will write additional blog entries in the coming days that show more of its features, in a digestible form.
In the short term, measurement researchers can request access to the infrastructure to run vetted experiments by emailing ark-info at caida.org. Note: the access does not provide a login on any of the Ark nodes. Rather, it provides access to a system that can access the measurement primitives of the vantage points, as illustrated above. Again, we are releasing the python module to allow researchers to develop and debug experiments locally, before running them on Ark. We hope that this approach provides a convenient development lifecycle for researchers, as the CAIDA system you will have access to when running the experiments will not necessarily have the local development environment that you are accustomed to.
The module itself is written in cython, providing a wrapper around two C libraries in scamper that do much of the heavy lifting. You build and install the module using the instructions on the scamper website, install the module using the Ubuntu PPA (preferred if you are using Ubuntu), or install the module using one of the packages available on other operating systems as these become available.