CAIDA’s 2022 Annual Report
Monday, July 10th, 2023 by kcThe CAIDA annual report summarizes CAIDA’s activities for 2022 in the areas of research, infrastructure, data collection and analysis. The executive summary is excerpted below:
(more…)
The CAIDA annual report summarizes CAIDA’s activities for 2022 in the areas of research, infrastructure, data collection and analysis. The executive summary is excerpted below:
(more…)
In December 2021, CAIDA published a method and system to automatically learn rules that extract geographic annotations from router hostnames. This is a challenging problem, because operators use different conventions and different dictionaries when they annotate router hostnames. For example, in the following figure, operators have used IATA codes (“iad”, “was”), a CLLI prefix (“asbnva”), a UN/LOCODE (“usqas”), and even city names (“ashburn”, “washington”) to refer to routers in approximately the same location — Ashburn, VA, US. Note that “ash” (router #4) is an IATA code for Nashua, NH, US, that the operators of he.net and seabone.net used to label routers in Ashburn, VA, US. Some operators also encoded the country (“us”) and state (“va”).
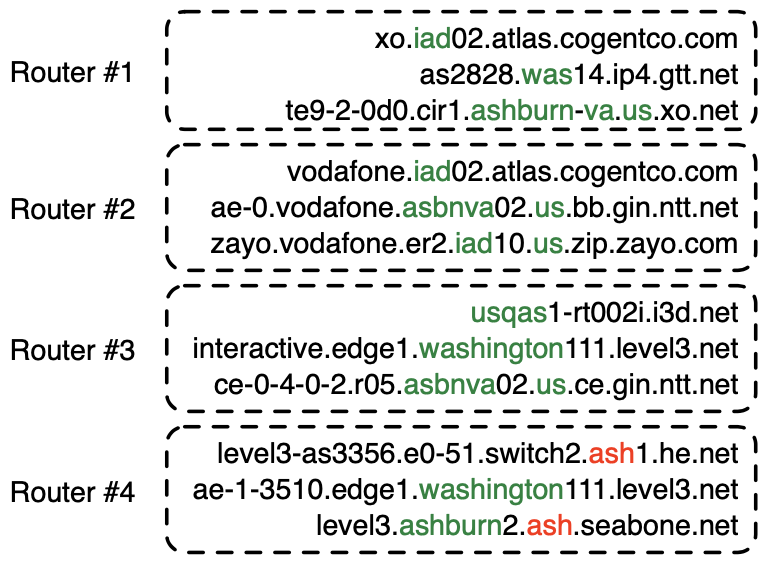
Our system, Hoiho, released as open-source as part of scamper, uses CAIDA’s Macroscopic Internet Topology Data Kit (ITDK) and observed round trip times to infer regular expressions that extract these apparent geolocation hints from hostnames. The ITDK contains a large dataset of routers with annotated hostnames, which we used as input to Hoiho for it infer rules (encoded as regular expressions) that extract these annotations. CAIDA has released these inferred rulesets in recent ITDKs.
Today, CAIDA is launching an API (api.hoiho.caida.org) and web front end (hoiho.caida.org) which returns extracted geographic locations from a user-provided list of DNS names. The API uses the rules that CAIDA infers with each ITDK. For embedded IATA, UN/LOCODE, and city names, the API returns the city name and a lat/long representing the location. For embedded CLLI codes, the API returns the CLLI code; please contact iconectiv for a dictionary that maps CLLI codes to locations.
Try the API out, and let us know if you find it useful!
Since May 9th, 2005, CAIDA has produced a data set that maps IPv4 prefixes (and later also IPv6 prefixes) to the AS (Autonomous System) originating that prefix into the global BGP routing system, as observed via a single BGP data collector of the Route Views data collection system. We have called this data set “RouteViews Prefix to AS”. We used CAIDA’s straighten_rv script to filter the RIB (routing information base file used as input data. We will discontinue this data set on December 31st, 2022 an replace it with a new more complete data set that we call CAIDA’s Prefix-to-AS data set.
CAIDA will use the BGPStream software package (and in particular the bgpview library) to include data from all available BGP collectors from both of the primary global publicly available collection systems: Route Views and RIPE NCC Routing Information Service. We will backfill Prefix-to-AS data to 2000. As part of this transition, CAIDA will no longer use straighten_rv to preprocess AS paths. We will create two files: an annotated file with all the data observed in BGP, and a simple file that filters out data of no interest to many researchers as described below.
Annotated files. The annotated file will include information about the stability and visibility of prefixes by different peers and collectors. Individuals who wish to produce a more refined mapping can fairly easily filter this data. The table below compares the older “Routeviews2” (a single Route Views collector) and the new annotated CAIDA Prefix-to-AS dataset (all collectors from both RIPE RIS and Route Views) for 1 June 2022. Most (99.6%) ASes and (87.2%) prefixes appeared in both datasets. Note that multiple ASNs announced the prefix 0.0.0.0/0, we exclude it since it covers the entire IPv4 address space.
| ASN | filtered | Routeviews2 only | Routeviews+RIPE | both | total | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Multiorigin/set | 128 | 4.10% | 1552 | 49.73% | 1441 | 46.17% | 3121 | ||||||
| public | 0 | 0.00% | 295 | 0.40% | 73294 | 99.60% | 73589 | ||||||
| reserved | X | 0 | 0.00% | 1379 | 88.97% | 171 | 11.03% | 1550 | |||||
| Prefix | filtered | Routeviews2 only | Routeviews+RIPE | both | total | ||||||||
| larger then /8 | X | 0 | 0.00% | 1 | 100.00% | 0 | 0.00% | 1 | |||||
| private | X | 0 | 0.00% | 504 | 84.85% | 90 | 15.15% | 594 | |||||
| public | 0 | 0.00% | 138498 | 12.81% | 942469 | 87.19% | 1080967 | ||||||
Simple files. The simple file will exclude very large prefixes, e.g., with mask lengths < 8, private addresses (RFC 1918), or prefixes announced exclusively by reserved ASNs (Special-Purpose ASN). The resulting simple prefix-to-ASN mapping covers 99.7% of the address space captured by the annotated file. In the table below (also reflecting 1 June 2022), 0.94% of prefixes and 0.42% of addresses had an additional origin AS that was not also observed in the Routeviews2-only dataset. This reflects the expanded visibility of more collectors and peer. 4.92% of CAIDA’s prefixes and 1.82% of addresses were not covered by Routeviews2-only prefix2as. Overall the combined data set provides visibility of 5.86% of prefixes and 2.24% of addresses not covered by routeviews2-only.
CAIDA’s Prefix to AS “simple” (99.7% of addresses observed in annotated files)
| ASN type | prefixes | addressses | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| source | agreement | Routeviews2 only |
Routeviews + RIPE |
number | group % | all % | number | group % | all % | |||||||||
| both | different | multiorigin | multiorigin | 626 | 11.43% | 0.11% | 1241088 | 9.65% | 0.04% | |||||||||
| public | multiorigin | 4816 | 87.95% | 0.82% | 11442617 | 88.93% | 0.37% | |||||||||||
| set | multiorigin | 34 | 0.62% | 0.01% | 183039 | 1.42% | 0.01% | |||||||||||
| 5476 | 100.00% | 0.94% | 12866744 | 100.00% | 0.42% | |||||||||||||
| both | same | multiorigin | multiorigin | 9869 | 1.79% | 1.69% | 12609229 | 0.42% | 0.41% | |||||||||
| public | public | 540032 | 98.20% | 92.45% | 2988739528 | 99.58% | 97.35% | |||||||||||
| set | set | 8 | 0.00% | 0.00% | 9216 | 0.00% | 0.00% | |||||||||||
| 549909 | 100.00% | 94.14% | 3001357973 | 100.00% | 97.76% | |||||||||||||
| Routeviews+RIPE | N/A | multiorigin | 1884 | 6.55% | 0.32% | 908601 | 1.63% | 0.03% | ||||||||||
| public | 26856 | 93.44% | 4.60% | 54919321 | 98.37% | 1.79% | ||||||||||||
| set | 2 | 0.01% | 0.00% | 2816 | 0.01% | 0.00% | ||||||||||||
| 28742 | 100.00% | 4.92% | 55830738 | 100.00% | 1.82% | |||||||||||||
You can find the new CAIDA Prefix-to-AS Mapping Data Set here.
ACM’s Internet Measurement Conference (IMC) is an annual highly selective venue for the presentation of Internet measurement and analysis research. The average acceptance rate for papers is around 25%. CAIDA researchers co-authored five papers and 3 posters that will be presented at this conference in Nice, France on October 25 – 27, 2022. We link to these publications below.
Investigating the impact of DDoS attacks on DNS infrastructure. Rafaele Sommese, KC Claffy, Roland van Rijswijk-Deij, Arnab Chattopadhyay, Alberto Dainotti, Anna Sperotto, and Mattijs Jonker. 2022. This paper describes a newly developed scalable method to map DDoS attacks targeting or affecting DNS infrastructure. The measurements reveal evidence that millions of domains experienced DDoS attacks during the recent 17-month observation window. Most attacks did not observably harm DNS performance, but in some cases, a 100-fold increase in DNS resolution time was observed. This research corroborates the value of known best practices to improve DNS resilience to attacks, including the use of anycast and topological redundancy in nameserver infrastructure.
Mind Your MANRS: Measuring the MANRS Ecosystem. Ben Du, Cecilia Testart, Romain Fontugne, Gautam Akiwate, Alex C. Snoeren, and kc claffy. 2022. Mutually Agreed on Norms on Routing Security (MANRS) is an industry-led initiative to improve Internet routing security by encouraging participating networks to implement a set of recommended actions. The goal of the paper is to evaluate the current state of the MANRS initiative in terms of its participants, their routing behavior, and its impact on the broader routing ecosystem, and discuss potential improvements. The findings confirm that MANRS participants are more likely to follow best practices than other similar networks on the Internet. However, within MANRS, not all networks take the MANRS mandate with the same rigor. This study demonstrates the need to continually assess the conformance of members for the prosperity of the MANRS initiative, and the challenges in automating such conformance checks.
Retroactive Identification of Targeted DNS Infrastructure Hijacking. Gautam Akiwate, Rafaele Sommese, Mattijs Jonker, Zakir Durumeric, kc Claffy, Geofrey M. Voelker, and Stefan Savage. 2022. DNS infrastructure tampering attacks are particularly challenging to detect because they can be very short-lived, bypass the protections of TLS and DNSSEC, and are imperceptible to users. Identifying them retroactively is further complicated by the lack of fine-grained Internet-scale forensic data. This paper is the first attempt to make progress toward this latter goal. Combining a range of longitudinal data from Internet-wide scans, passive DNS records, and Certificate Transparency logs, we have constructed a methodology for identifying potential victims of sophisticated DNS infrastructure hijacking and have used it to identify a range of victims (primarily government agencies). The authors analyze possible best practices in terms of their measurability by third parties, including a review of DNS measurement studies and available data sets.
Stop, DROP, and ROA: Effectiveness of Defenses through the lens of DROP. Leo Oliver, Gautam Akiwate, Matthew Luckie, Ben Du, and kc claffy. 2022. Malicious use of the Internet address space has been a persistent threat for decades. Multiple approaches to prevent and detect address space abuse include the use of blocklists and the validation against databases of address ownership such as the Internet Routing Registry (IRR) databases and the Resource Public Key Infrastructure (RPKI). The authors undertook a study of the effectiveness of these routing defenses through the lens of one of the most respected blocklists on the Internet: Spamhaus’ Don’t Route Or Peer (DROP) list. The authors show that attackers are subverting multiple defenses against malicious use of address space, including creating fraudulent Internet Routing Registry records for prefixes shortly before using them. Other attackers disguised their activities by announcing routes with spoofed origin ASes consistent with historic route announcements. The authors quantify the substantial and actively-exploited attack surface in unrouted address space, which warrants reconsideration of RPKI eligibility restrictions by RIRs, and reconsideration of AS0 policies by both operators and RIRs.
Where .ru? Assessing the Impact of Conflict on Russian Domain Infrastructure. Mattijs Jonker, Gautam Akiwate, Antonia Afnito, kc claffy, Alessio Botta, Geofrey M. Voelker, Roland van Rijswijk-Deij, and Stefan Savage. 2022. The hostilities in Ukraine have driven unprecedented forces, both from third-party countries and in Russia, to create economic barriers. In the Internet, these manifest both as internal pressures on Russian sites to (re-)patriate the infrastructure they depend on (e.g., naming and hosting) and external pressures arising from Western providers disassociating from some or all Russian customers. This paper describes longitudinal changes in the makeup of naming, hosting, and certificate issuance for domains in the Russian Federation due to the war in Ukraine.
CAIDa also contributed to three extended abstracts:
“Observable KINDNS: Validating DNS Hygiene.” Sommese, Raffaele, Mattijs Jonker, kc claffy. ACM Internet Measurement Conference (IMC) Poster, 2022.
“PacketLab – Tools Alpha Release and Demo.“ Yan, Tzu-Bin, Yuxuan Chen, Anthea Chen, Zesen Zhang, Bradley Huffaker, Ricky K. P. Mok, Kirill Levchenko, kc claffy. ACM Internet Measurement Conference (IMC) Poster, 2022.
“A Scalable Network Event Detection Framework for Darknet Traffic.”Gao, Max, Ricky K. P. Mok, kc claffy. ACM Internet Measurement Conference (IMC) Poster, 2022.
The CAIDA annual report summarizes CAIDA’s activities for 2021 in the areas of research, infrastructure, data collection and analysis. Our research projects span: Internet cartography and performance; security, stability, and resilience studies; economics; and policy. Our infrastructure, software development, and data sharing activities support measurement-based Internet research, both at CAIDA and around the world, with focus on the health and integrity of the global Internet ecosystem.
The executive summary is excerpted below:
(more…)
The Border Gateway Protocol (BGP) is the protocol that networks use to exchange (announce) routing information across the Internet. Unfortunately, BGP has no mechanism to prevent the propagation of false announcements such as hijacks and misconfigurations. The Internet Route Registry (IRR) and Resource Public Key Infrastructure (RPKI) both emerged as different solutions to improve routing security and operation in the Border Gateway Protocol (BGP) by allowing networks to register information and develop route filters based on information other networks have registered.
The Internet Routing Registry (IRR) was first introduced in 1995 and remained a popular tool for BGP route filtering. However, route origin information in the IRR suffers from inaccuracies due to the lack of incentive for registrants to keep information up to date and the use of non-standardized validation procedures across different IRR database providers.
Over the past few years, the Resource Public Key Infrastructure (RPKI), a system providing cryptographically attested route origin information, has seen steady growth in its deployment and has become widely used for Route Origin Validation (ROV) among large networks.
Some networks are unable to adopt RPKI filtering due to technical or administrative reasons and continue using only existing IRR-based route filtering. Such networks may not be able to construct correct routing filters due IRR inaccuracies and thus compromise routing security.
In our paper IRR Hygiene in the RPKI Era, we at CAIDA (UC San Diego), in collaboration with MIT, study the scale of inaccurate IRR information by quantifying the inconsistency between IRR and RPKI. In this post, we will succinctly explain how we compare records and then focus on the causes of such inconsistencies and provide insights on what operators could do to keep their IRR records accurate.
For our study we downloaded IRR data from 4 IRR database providers: RADB, RIPE, APNIC, and AFRINIC, and RPKI data from all Trust Anchors published by the RIPE NCC. Figure 1 shows IRR cover more IPv4 address space than RPKI, but RPKI grew faster than IRR, having doubled its coverage over the past 6 years.
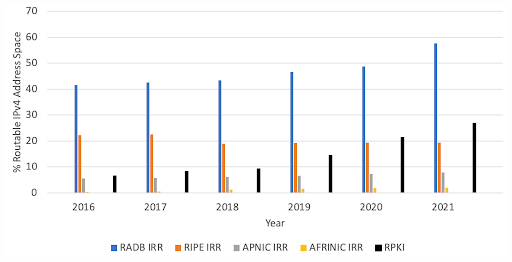 Figure 1. IPv4 coverage of IRR and RPKI databases. RADB, the largest IRR database, has records representing almost 60% of routable IPv4 address space. In contrast, the RPKI covers almost 30% of that address space but has been steadily growing in the past few years.
Figure 1. IPv4 coverage of IRR and RPKI databases. RADB, the largest IRR database, has records representing almost 60% of routable IPv4 address space. In contrast, the RPKI covers almost 30% of that address space but has been steadily growing in the past few years.
We classified IRR records following the procedure in Figure 2: first we check if there is a Route Origin Authorization (ROA) record in RPKI covering the IRR record, then in case there is one if the ASN is consistent, and finally, if the ASN is consistent, we check the prefix length compared to the maximum length attribute of RPKI records. Using this procedure we are left with 4 categories:
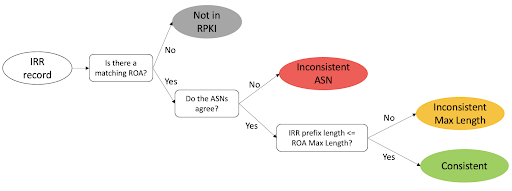
Figure 2. Classification of IRR records
As of October 2021, we found only 38% of RADB records with matching ROAs were consistent with RPKI, meaning that there were more inconsistent records than consistent records in RADB, see Figure 3 (left) . In contrast, 73%, 98%, and 93% of RIPE, APNIC, and AFRINIC IRR records were consistent with RPKI, showing a much higher consistency than RADB, see Figure 3 (right).
We attribute the big difference in consistency to a few reasons. First, the IRR database we collected from the RIRs are their respective authoritative databases, meaning the RIRs manages all the prefixes, and verifies the registration of IRR objects with address ownership information. This verification process is stricter than that of RADB and leads to the higher quality of IRR records. Second, APNIC provides its registrants a management platform that automatically creates IRR records for a network when it registers its prefixes in RPKI. This platform contributes to a larger number of consistent records compared to other RIRs.
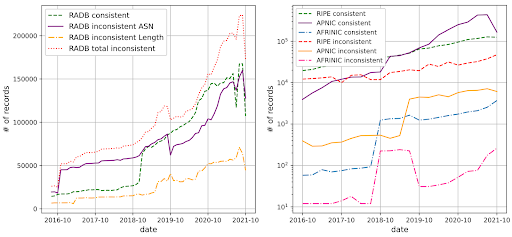
Figure 3. RIR-managed IRR databases have higher consistency with RPKI compared to RADB.
In our analysis we found that inconsistent max length was mostly caused by IRR records that are too specific, as the example shown in Figure 4, and to a lesser extent by misconfigured max length attribute in RPKI. We also found that inconsistent ASN records are largely caused by customer networks failing to remove records after returning address space to their provider network, such as the example in Figure 5.
Inconsistent Max Length (Figure 4)

Figure 4. IRR record with inconsistent max length: the IRR prefix length exceeds the RPKI max length value.
Inconsistent ASN (Figure 5)

Figure 5. IRR record with inconsistent ASN: the IRR record ASN differs from the RPKI record ASN.
Although RPKI is becoming more widely deployed, we do not see a decrease in IRR usage, and therefore we should improve the accuracy of information in the IRR. We suggest that networks keep their IRR information up to date and IRR database providers implement policies that promote good IRR hygiene.
Networks currently using IRR for route filtering can avoid the negative impact of inaccurate IRR information by using IRRd version 4, which validates IRR information against RPKI, to ignore incorrect IRR records.
A year ago January 2020, k claffy, CAIDA Director and UCSD Adjunct Professor of Computer Science and Engineering responded with collaborator David Clark, Senior Scientist at MIT’s Computer Science and Artificial Intelligence Laboratory to the Request for Information (RFI) put out by the National Science and Technology Council’s (NSTC) Joint Committee on the Research Environment (JCORE). The response establishes the critical importance of the internet to the infrastructure of society and the need for governments, and specifically the U.S. government, to send a strong signal to the private sector through high-level policy making that the only path to understanding the characteristics of the internet comes via data sharing and that responsible sharing of data for documented scientific research will not generate corporate liability.
Another focus and benefit to the policy for which we call comes with the development and delivery of academic training of professionals to work with large data sets focused on communications and networking.
You can see the complete response and more related material posted in CAIDA resource catalog.
The recent Cyberspace Solarium Commission report (1) set out a strategic plan to improve the security of cyberspace. Among its many recommendations is that the government establish a Bureau of Cyber Statistics, to provide the government with the information that it needs for informed planning and action. A recent report from the Aspen Institute echoed this call. (2) Legal academics and lobbyists have already started to consider its structure. (3) The Internet measurement community needs to join this conversation.
The Solarium report proposed some specific characteristics: they recommend a bureau located in the Department of Commerce, and funded and authorized to gather necessary data. The report also says that “the center should be funded and equipped to host academics as well as private sector and independent security researchers as a part of extended exchanges”. We appreciate that the report acknowledges the value of academic researchers and that this objective requires careful thought to achieve. The report specifically mentions “purchasing private or proprietary data repositories”. Will “extended exchanges” act as the only pattern of access, where an academic would work under a Non-Disclosure Agreement (NDA), unable to publish results that relied on proprietary data? Would this allow graduate students to participate, i.e., how would they publish a thesis? The proposal does not indicate deep understanding of how academic research works. As an illustrative example, CAIDA/UCSD and MIT were hired by AT&T as “independent measurement experts” to propose and oversee methods for AT&T to satisfy FCC reporting requirements imposed as a merger condition. (4) AT&T covered all the data we received by an NDA, and we were not able to publish any details about what we learned. This sort of work does not qualify as academic research. It is consulting.
In our view, the bureau must be organized in such a way that academics are able and incentivized to utilize the resources of the bureau for research on questions that motivate the creation of the bureau in the first place. But this requires that when the U.S. government establishes the bureau, it makes apparent the value of academic participation and the modes of operation that will allow it.
These reports focus on cybersecurity, and indeed, security is the most prominent national challenge of the Internet. But the government needs to understand many other issues related to the character of the Internet ecosystem, many of which are inextricably related to security. We cannot secure what we do not understand, and we cannot understand what we do not measure. Measurement of the Internet raises epistemological challenges that span many disciplines, from network engineering and computer science to economics, sociology, ethics, law, and public policy. The following guiding principles can help accommodate these challenges, and the sometimes conflicting incentives across academic, government, commercial, and civic stakeholders.
Other parts of the globe have moved to regularize cybersecurity data, and they have explicitly recognized the importance of engaging and sustaining the academic research establishment in developing cybersecurity tools to secure network infrastructure (5). If the U.S. does not take coherent steps to support its research community, there is a risk that it is sidelined in shaping the future of the Internet. The European Union’s proposed regulation for Digital Services (6) also discussed the importance of ensuring access to proprietary data by the academic research community:
Investigations by researchers on the evolution and severity of online systemic risks are particularly important for bridging information asymmetries and establishing a resilient system of risk mitigation, informing online platforms, Digital Services Coordinators, other competent authorities, the Commission and the public. This Regulation therefore provides a framework for compelling access to data from very large online platforms to vetted researchers.
They clarify what they mean by “vetted researchers”:
In order to be vetted, researchers shall be affiliated with academic institutions, be independent from commercial interests, have proven records of expertise in the fields related to the risks investigated or related research methodologies, and shall commit and be in a capacity to preserve the specific data security and confidentiality requirements corresponding to each request.
This regulation emphasizes a structure that allows the academic community to work with proprietary data, sending an important signal that they intend to make their academic research establishment a recognized part of shaping the future of the Internet in the EU. The U.S. needs to take a similar proactive stance.
References
 Figure 1: This picture shows a line of floating buoys that designate the path of the long-awaited SACS (South-Atlantic Cable System). This submarine cable now connects Angola to Brazil (Source: G Massala, https://www.menosfios.com/en/finally-cable-submarine-sacs-arrived-to-brazil/, Feb 2018.)
Figure 1: This picture shows a line of floating buoys that designate the path of the long-awaited SACS (South-Atlantic Cable System). This submarine cable now connects Angola to Brazil (Source: G Massala, https://www.menosfios.com/en/finally-cable-submarine-sacs-arrived-to-brazil/, Feb 2018.)
The network layer of the Internet routes packets regardless of the underlying communication media (Wifi, cellular telephony, satellites, or optical fiber). The underlying physical infrastructure of the Internet includes a mesh of submarine cables, generally shared by network operators who purchase capacity from the cable owners [2,11]. As of late 2020, over 400 submarine cables interconnect continents worldwide and constitute the oceanic backbone of the Internet. Although they carry more than 99% of international traffic, little academic research has occurred to isolate end-to-end performance changes induced by their launch.
In mid-September 2018, Angola Cables (AC, AS37468) activated the SACS cable, the first trans-Atlantic cable traversing the Southern hemisphere [1][A1]. SACS connects Angola in Africa to Brazil in South America. Most assume that the deployment of undersea cables between continents improves Internet performance between the two continents. In our paper, “Unintended consequences: Effects of submarine cable deployment on Internet routing”, we shed empirical light on this hypothesis, by investigating the operational impact of SACS on Internet routing. We presented our results at the Passive and Active Measurement Conference (PAM) 2020, where the work received the best paper award [11,7,8]. We summarize the contributions of our study, including our methodology, data collection and key findings.
[A1] Note that in the same year, Camtel (CM, AS15964), the incumbent operator of Cameroon, and China Unicom (CH, AS9800) deployed the 5,900km South Atlantic Inter Link (SAIL), which links Fortaleza to Kribi (Cameroon) [17], but this cable was not yet lit as of March 2020.
![]() One of CAIDA’s primary missions has been to improve our understanding of the Internet infrastructure, through data-driven science. To this end, CAIDA has collected and maintains one of the largest collections of Internet-related data sets in the world, and developed tools and services to curate and process that data. Along with this success has come the challenge of helping new students and researchers to find and use that rich archive of resources.
One of CAIDA’s primary missions has been to improve our understanding of the Internet infrastructure, through data-driven science. To this end, CAIDA has collected and maintains one of the largest collections of Internet-related data sets in the world, and developed tools and services to curate and process that data. Along with this success has come the challenge of helping new students and researchers to find and use that rich archive of resources.
As part of our NSF-funded DIBBS project, CAIDA has developed a rich context resource catalog, served at catalog.caida.org. The goal of the catalog is to help both newcomers and experienced users with data discovery, and reducing the time between finding the data and extracting knowledge and insights from it.
In addition to linking datasets to related papers and presentations, the catalog will also link to code snippets, user-provided notes, and recipes for performing commons analytical tasks with the data.
The catalog can be found at: https://catalog.caida.org
![]()
Please explore and provide feedback!