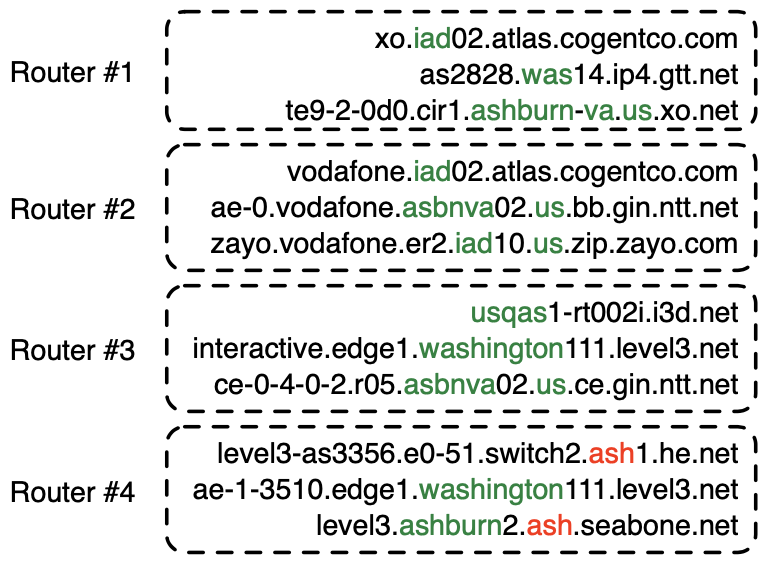
In December 2021, CAIDA published a method and system to automatically learn rules that extract geographic annotations from router hostnames. This is a challenging problem, because operators use different conventions and different dictionaries when they annotate router hostnames. For example, in the following figure, operators have used IATA codes (“iad”, “was”), a CLLI prefix (“asbnva”), a UN/LOCODE (“usqas”), and even city names (“ashburn”, “washington”) to refer to routers in approximately the same location — Ashburn, VA, US. Note that “ash” (router #4) is an IATA code for Nashua, NH, US, that the operators of he.net and seabone.net used to label routers in Ashburn, VA, US. Some operators also encoded the country (“us”) and state (“va”).
Our system, Hoiho, released as open-source as part of scamper, uses CAIDA’s Macroscopic Internet Topology Data Kit (ITDK) and observed round trip times to infer regular expressions that extract these apparent geolocation hints from hostnames. The ITDK contains a large dataset of routers with annotated hostnames, which we used as input to Hoiho for it infer rules (encoded as regular expressions) that extract these annotations. CAIDA has released these inferred rulesets in recent ITDKs.
Today, CAIDA is launching an API (api.hoiho.caida.org) and web front end (hoiho.caida.org) which returns extracted geographic locations from a user-provided list of DNS names. The API uses the rules that CAIDA infers with each ITDK. For embedded IATA, UN/LOCODE, and city names, the API returns the city name and a lat/long representing the location. For embedded CLLI codes, the API returns the CLLI code; please contact iconectiv for a dictionary that maps CLLI codes to locations.
Try the API out, and let us know if you find it useful!
[HOIHO] Luckie, M., Huffaker, B., Marder, A., Bischof, Z., Fletcher, M., and claffy, k., 2021. “Learning to Extract Geographic Information from Internet Router Hostnames.” ACM SIGCOMM Conference on emerging Networking EXperiments and Technologies (CoNEXT),
https://catalog.caida.org/paper/2021_learning_extract_geographic_information