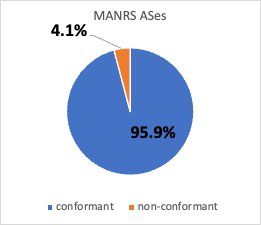
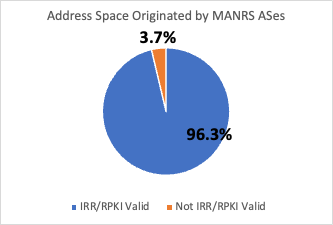
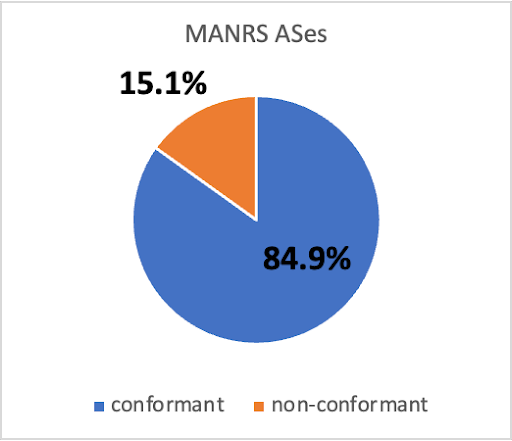
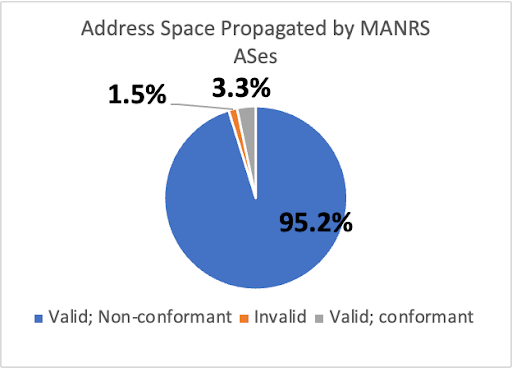
A First Look at Suspicious IRR Records
February 15th, 2024 by Ben DuThe Internet Routing Registry (IRR) is a set of distributed databases used by networks to register routing policy information and to validate messages received in the Border Gateway Protocol (BGP).
First deployed in the 1990s, the IRR remains the most widely used database for routing security purposes, despite the existence of more recent and more secure alternatives such as the Resource Public Key Infrastructure (RPKI). Yet, the IRR lacks a strict validation standard and the limited coordination across different database providers can lead to inaccuracies. Moreover, it has been reported that attackers have begun to register false records in the IRR to bypass operators’ defenses when launching attacks on the Internet routing system, such as BGP hijacks.
In our paper, IRRegularities in the Internet Routing Registry, we at CAIDA/UC San Diego, in collaboration with Georgia Tech and Stanford, proposed a workflow to identify suspicious IRR records. In this post, we succinctly describe how we quantified the inconsistencies across all IRR databases, identified likely suspicious IRR records, and validated our results against relevant studies.
Reported false IRR records
Each IRR database is managed independently under different policies and registration processes. The five RIRs (RIPE, ARIN, APNIC, AFRINIC, and LACNIC) manage authoritative IRR databases. Routing information registered in those IRR databases undergoes a validation process against the address ownership information to ensure correctness. IRR databases operated by other institutions are non-authoritative IRR databases and are not strictly validated.
To increase the likelihood of launching a successful BGP hijack attack, malicious actors may inject false records into non-authoritative IRR databases. There have been reported cases of successful BGP hijacking attempts that also abused the IRR.
In one prominent case, an attacker successfully hijacked Amazon’s address space that was used to host Celer Network’s cryptocurrency exchange website. The attacker falsely registered objects in ALTDB using QuickHost.uk’s AS number (AS209243) and pretended to be an upstream provider of AS16509 (Amazon). In a different case, attackers registered false IRR objects under AS207427 (GoHosted.eu) for 3 UCSD-announced prefixes and hijacked those prefixes in BGP for more than a month.
Workflow to identify suspicious IRR records
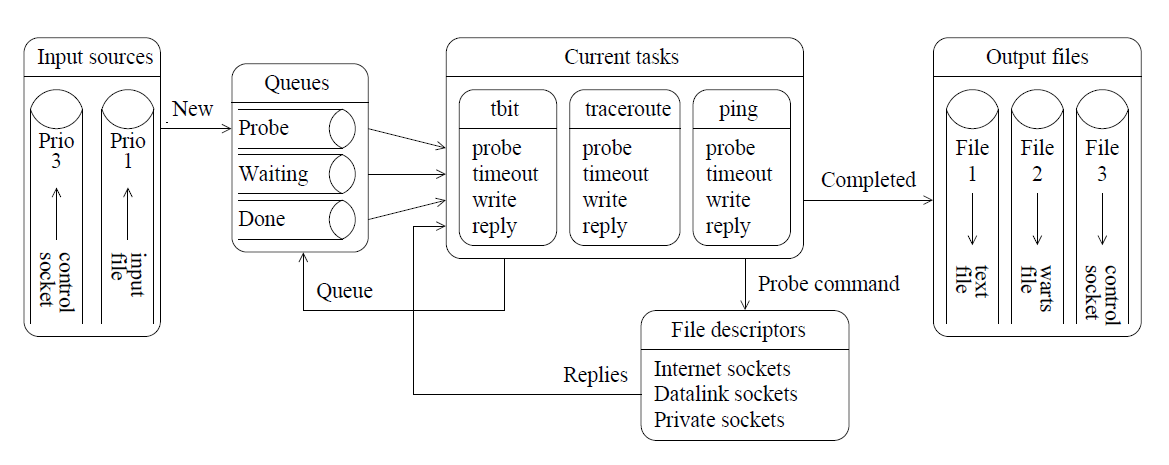
Following the diagram in Figure 1, we consider an IRR record in a non-authoritative database suspicious if it satisfies the following conditions:
- The IRR record conflicted with corresponding records (containing the same prefix but different origin) in the authoritative IRR database.
- The prefix in the IRR record from step 1 was originated in BGP by multiple ASes, one of which is the AS in the IRR record.
We validate our inferred suspicious IRR records with the Resource Public Key Infrastructure (RPKI), a more recent and secure alternative of the IRR. We also check if the origin ASes in the suspicious IRR records were classified as serial hijacker ASes by Testart et al. published at IMC 2019.

Figure 1. Workflow to identify suspicious IRR records (solid arrows) and methods to validate our results (dotted arrows).
Baseline: Inconsistency across IRR databases
We discuss the results of the first step in the workflow above. To understand the baseline characteristics of the IRR databases, we analyze the consistency between all pairs of IRR databases.
Figure 2 shows the percentage of records with the same prefix but different origin ASes between pairs of IRRs. We found that most IRR databases have mismatching records with one another, consistent with persistent neglect by IRR users and thus an increasing number of outdated entries. We also noticed instances where a company registered records in multiple IRR databases, but only updated the records in one IRR database, causing inter-IRR inconsistency.
Most surprising were the mismatching records between pairs of authoritative IRR databases, since each RIR only allows registration of records containing address blocks managed by that RIR, which do not overlap with each other. We speculate that those mismatching records correspond to address space that was transferred across RIRs, and the address owner from the previous RIR did not remove the outdated object. As of January 2024, two months since our paper was published, the RIRs have removed all inconsistent IRR records in their authoritative databases. We provide the updated results on github https://github.com/CAIDA/IRR-IRRegularities-Analysis

Figure 2. Fraction of inconsistent records in the IRR on the Y-axis with respect to the IRR on the X-axis. The denominators shown in Figure 1b in the paper.
Suspicious records in RADB
Out of 1.5 million RADB records (1.2 million unique prefixes), we identified 34,199 potentially suspicious records. We further checked the RPKI consistency of those records. Out of those 34,199 records, 4,082 records had a mismatching ASN, 144 had prefixes that were too specific, and 9,450 had no matching ROA in RPKI. To further narrow down the list of suspicious IRR records, we removed the ones whose AS appear in other RPKI-consistent records (assuming those ASes were unlikely to be malicious), leaving 6,373 suspicious records. Network operators who use IRR-based filtering should carefully consider those suspicious records.
We also compared our list of 34,199 suspicious records with the list of serial hijackers from Testart et al. and found 5,581 records registered by 168 serial hijacker ASes. We found one of those ASes to be a small US-based ISP with 10 customers according to CAIDA’s AS Rank. Another serial hijacker AS was a European hosting provider with more than 100 customers, which was also known to be exploited by attackers to abuse the DNS system. However, networks may have registered both suspicious and benign records, which can complicate the inference of suspicious IRR records.
Summary
We provided a first look at inconsistencies across IRR databases and proposed an approach to infer suspicious activities in the IRR without external sources of ground truth. We found IRR databases prone to staleness and errors, confirming the importance of operators transitioning to RPKI-based filtering. We hope this work inspires new directions in automating the detection of abuse of IRRs, ideally in time to prevent or thwart an attacker’s ultimate objective. We publicly provide our analysis code on Github https://github.com/CAIDA/IRR-IRRegularities-Analysis with more recent sample data and results.