Executive summary:
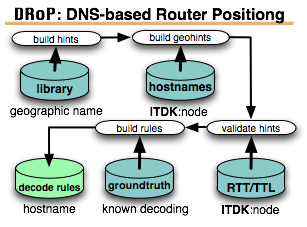
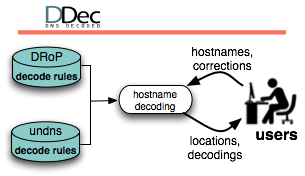
This program plan outlines CAIDA’s anticipated activities for 2014-2017, in the areas of research, infrastructure, data collection and analysis to support the research community. Our research projects span Internet topology, routing, security, economics, future Internet architectures, and policy. We will continue to pursue Internet cartography, improving our IPv4 and IPv6 topology mapping capabilities using our expanding and extensible Ark measurement infrastructure. We will improve the accuracy and sophistication of our topology annotation capabilities, including economic information and business relationships between ISPs. Using our evolving alias resolution measurement system, which integrates and improves on the best available technology for IP address alias resolution, we will continue to collect, curate, and release our Internet Topology Data Kit (ITDK), including simplified versions that are easier for researchers to use.
We will use this infrastructure and rich data sets to support a new project: Mapping Interconnection in the Internet: Colocation, Connectivity and Congestion. The goal of this project is to characterize the changing nature of the Internet’s topology and traffic dynamics, and to investigate the implications of these changes on network science, architecture, operations, and public policy. We will construct a new type of semantically rich Internet map to guide a study of congestion induced by evolving peering and traffic management practices of CDNs and ISPs, including methods to detect and localize the congestion to specific points in wired (and hopefully eventually mobile) networks. Ark will also support our ongoing (entering its third year) project to study large-scale disruptions of Internet connectivity via correlation of a variety of disparate sources of data; We will have a outage-detection system operational by the end of 2015. Finally, we will extend our participation in future Internet research in two dimensions: measuring and modeling IPv6 deployment; and an expanded role in the Named Data Networking project, one of the NSF-funded future Internet architecture projects headed into its fourth year.
Our infrastructure activities include developing, deploying, and operating an active measurement platform that cost-effectively supports global Internet research and security vulnerability analysis. We will expand our software infrastructure activities to include a system for allowing measurement of compliance with BCP38 (ingress filtering best practices) across government, research, and commercial networks, and analysis of resulting data. We will expand our data sharing efforts, making older topology and some traffic data sets public that used to be restricted to academic researchers. As always, we will lead and participate in tool development to support measurement, analysis, indexing, and dissemination of data from operational global Internet infrastructure. Our outreach activities will include peer-reviewed papers, workshops, blogging, presentations, and technical reports.
Note that not all of the activities described in this program plan are fully funded yet; we are seeking additional support to enable us to accomplish our ambitious agenda.
Finally, we are taking this opportunity of reflection and strategic planning to change the expansion of CAIDA’s acronym to more accurately match what we do. Effective this month we will be the Center for Applied Internet Data Analysis.
Our annual reports are at http://www.caida.org/home/about/annualreports/. This program plan is available at http://www.caida.org/home/about/progplan/. Feedback and questions are welcome at info at caida.org.