CAIDA’s 2022 Annual Report
Monday, July 10th, 2023 by kcThe CAIDA annual report summarizes CAIDA’s activities for 2022 in the areas of research, infrastructure, data collection and analysis. The executive summary is excerpted below:
(more…)
The CAIDA annual report summarizes CAIDA’s activities for 2022 in the areas of research, infrastructure, data collection and analysis. The executive summary is excerpted below:
(more…)
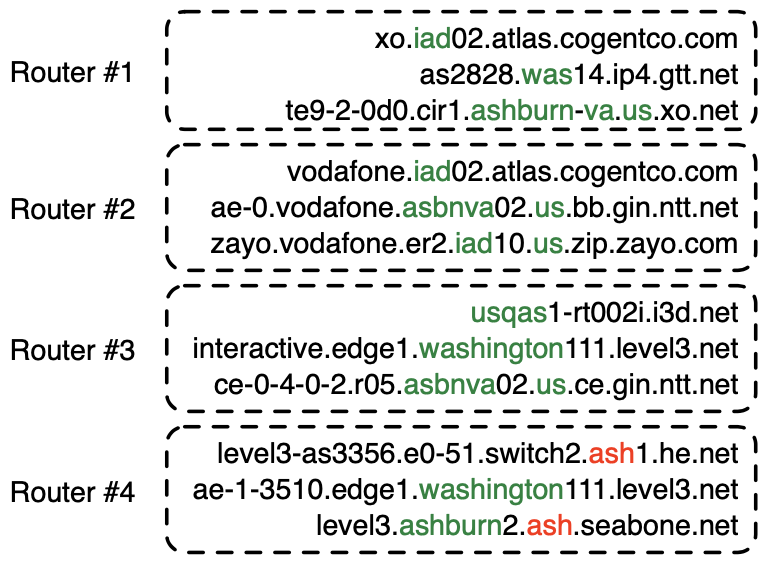
In December 2021, CAIDA published a method and system to automatically learn rules that extract geographic annotations from router hostnames. This is a challenging problem, because operators use different conventions and different dictionaries when they annotate router hostnames. For example, in the following figure, operators have used IATA codes (“iad”, “was”), a CLLI prefix (“asbnva”), a UN/LOCODE (“usqas”), and even city names (“ashburn”, “washington”) to refer to routers in approximately the same location — Ashburn, VA, US. Note that “ash” (router #4) is an IATA code for Nashua, NH, US, that the operators of he.net and seabone.net used to label routers in Ashburn, VA, US. Some operators also encoded the country (“us”) and state (“va”).
Our system, Hoiho, released as open-source as part of scamper, uses CAIDA’s Macroscopic Internet Topology Data Kit (ITDK) and observed round trip times to infer regular expressions that extract these apparent geolocation hints from hostnames. The ITDK contains a large dataset of routers with annotated hostnames, which we used as input to Hoiho for it infer rules (encoded as regular expressions) that extract these annotations. CAIDA has released these inferred rulesets in recent ITDKs.
Today, CAIDA is launching an API (api.hoiho.caida.org) and web front end (hoiho.caida.org) which returns extracted geographic locations from a user-provided list of DNS names. The API uses the rules that CAIDA infers with each ITDK. For embedded IATA, UN/LOCODE, and city names, the API returns the city name and a lat/long representing the location. For embedded CLLI codes, the API returns the CLLI code; please contact iconectiv for a dictionary that maps CLLI codes to locations.
Try the API out, and let us know if you find it useful!
The CAIDA annual report summarizes CAIDA’s activities for 2017, in the areas of research, infrastructure, data collection and analysis. Our research projects span Internet topology, routing, security, economics, future Internet architectures, and policy. Our infrastructure, software development, and data sharing activities support measurement-based internet research, both at CAIDA and around the world, with focus on the health and integrity of the global Internet ecosystem. The executive summary is excerpted below:
(more…)
As announced in the CAIDA blog “Further Improvements to the Internet Data Measurement Catalog (DatCat)” of August 26, 2014, the new Internet Data Measurement Catalogue DatCat is now operational. New entries by the community are welcome, and about a dozen have been added so far. We plan to advertise new and interesting entries on a regular basis with a short entry in this blog. This is the first contribution in this series.
Added on July 31, 2014, was the collection “DNS Zone Files”.
http://imdc.datcat.org/collection/1-0718-Y=DNS-Zone-Files;
contributed 2014-07-31 by Tristan Halvorson:
This collection contains Zone files with NS and A records for all new (2013 and later) TLDs.
ICANN has opened up the TLD creation process to a large number of new registries with a centralized service for downloading all of this new data. Each TLD has a separate zone file, and each zone file contains entries for every registered domain. This data collection contains step-by-step instructions to acquire this data directly from the registries through ICANN. This method only works for TLDs released during 2013 or later.
Reading about NASA’s recent DNSSEC snafu, and especially Comcast’s impressively cogent description of what went wrong (i.e., a mishap that seems way too easy to ‘hap’), I’m reminded of the page I found most interesting in The Checklist Manifesto:
[I posted the following on CircleID today:]
As is well known to most CircleID readers — but importantly, not to most other Internet users — in March 2011, ICANN knowingly and purposefully embraced an unprecedented policy that will encourage filtering, blocking, and/or redirecting entire virtual neighborhoods, i.e., “top-level domains” (TLDs). Specifically, ICANN approved the creation of the “.XXX” suffix, intended for pornography websites. Although the owner of the new .XXX TLD deems a designated virtual enclave for morally controversial material to be socially beneficial for the Internet, this claim obfuscates the dangers such a policy creates under the hood.
In response to the U.S. National Telecommunications and Information Administration’s recent Further Notice of Inquiry on the Internet Assigned Names and Numbers Authority (IANA) Functions [Docket No. 110207099-1319-0], I submitted the following comment:
In pursuit of more rigorous data on IPv6 deployment, CAIDA has undertaken four IPv6 measurement and analysis exercises: address allocation data; traceroute-based topology; DNS queries from root servers; and a global survey of network operators in 2008.
My recently submitted public comments on the increasingly controversial issue of ICANN’s plans to expand the generic Top Level Domain namespace indefinitely:
[I submitted the following public comment to ICANN in response to their second attempt at commissioning An Economic Framework for the Analysis of the Expansion of Generic Top-Level Domain Names. I’ll link to ICANN’s summary of all public comments on this report when available. -k]
This second economic report posted 16 june (pdf) is an improvement over the June 2009 reports by Dennis Carlton (pdf, pdf) but there are still too many — and too fundamental — flaws for it to serve as the basis of any ICANN policy on new gTLDs: